AutoScaling Suspend process
In ASG, on can suspend Launch or Terminate. In the below paragraph, we will see what happens on suspending for each action.
Terminate
- Your Auto Scaling group does not scale in for alarms or scheduled actions that occur while the process is suspended. In addition, the following processes are disrupted:
AZRebalanceis still active but does not function properly. It can launch new instances without terminating the old ones. This could cause your Auto Scaling group to grow up to 10 percent larger than its maximum size, because this is allowed temporarily during rebalancing activities. Your Auto Scaling group could remain above its maximum size until you resume theTerminateprocess. WhenTerminateresumes,AZRebalancegradually rebalances the Auto Scaling group if the group is no longer balanced between Availability Zones or if different Availability Zones are specified.ReplaceUnhealthyis inactive but notHealthCheck. WhenTerminateresumes, theReplaceUnhealthyprocess immediately starts running. If any instances were marked as unhealthy whileTerminatewas suspended, they are immediately replaced.
Launch
- Your Auto Scaling group does not scale out for alarms or scheduled actions that occur while the process is suspended.
AZRebalancestops rebalancing the group.ReplaceUnhealthycontinues to terminate unhealthy instances, but does not launch replacements. When you resumeLaunch, rebalancing activities and health check replacements are handled in the following way:AZRebalancegradually rebalances the Auto Scaling group if the group is no longer balanced between Availability Zones or if different Availability Zones are specified.ReplaceUnhealthyimmediately replaces any instances that it terminated during the time thatLaunchwas suspended.
Placement Group
Placement groups are three types. they are cluster, partition and spread.
Cluster placement group ensure that all instances are in same AZ. This can also be within Peered VPC of same region there by instances under this group enjoy high speed network of 10 GBPS
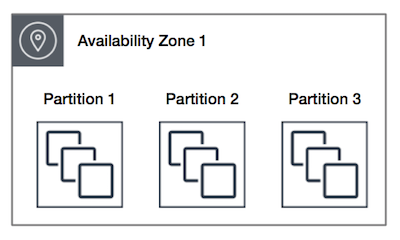
Partition placement groups help reduce the likelihood of correlated hardware failures for your application. The below picture explains more about Partition Placement group
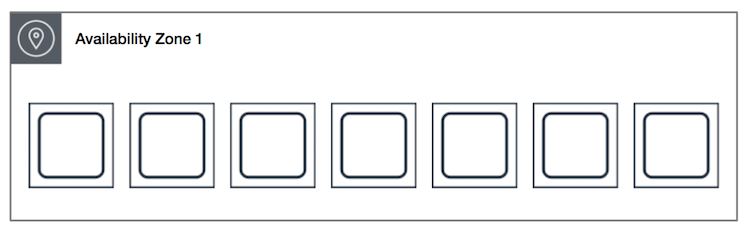
A spread placement group is a group of instances that are each placed on distinct racks, with each rack having its own network and power source.
Please remember for EC2 instance, only Current generation or Latest family instances only support IPV6
i.e M4, T3 etc. M3 and M2 instances does not support.
Server Order Preference option for ELB
Elastic Load Balancing supports the Server Order Preference option for negotiating connections between a client and a load balancer. During the SSL connection negotiation process, the client and the load balancer present a list of ciphers and protocols that they each support, in order of preference.
By default, the first cipher on the client’s list that matches any one of the load balancer’s ciphers is selected for the SSL connection. If the load balancer is configured to support Server Order Preference, then the load balancer selects the first cipher in its list that is in the client’s list of ciphers. This ensures that the load balancer determines which cipher is used for SSL connection. If you do not enable Server Order Preference, the order of ciphers presented by the client is used to negotiate connections between the client and the load balancer.
When using server-side encryption with customer-provided encryption keys (SSE-C), you must provide encryption key information using the following request headers:
x-amz-server-side-encryption-customer-algorithm: Use this header to specify the encryption algorithm. The header value must be “AES256”
x-amz-server-side-encryption-customer-key : Use this header to provide the 256-bit, base64-encoded encryption key for Amazon S3 to use to encrypt or decrypt your data.
x-amz-server-side-encryption-customer-key-MD5: Use this header to provide the base64-encoded 128-bit MD5 digest of the encryption key according to RFC 1321. Amazon S3 uses this header for a message integrity check to ensure the encryption key was transmitted without error.
Troubleshooting instance launch issues
Instance limit exceeded:
You get the InstanceLimitExceeded error when you try to launch a new instance or restart a stopped instance because you reached the limit of number of instances in the region. Log ticket to increase the limit
Insufficient instance capacity:
If you get an InsufficientInstanceCapacity error when you try to launch an instance or restart a stopped instance, AWS does not currently have enough available On-Demand capacity to service your request.To resolve the issue, try the following:
- Wait a few minutes and then submit your request again; capacity can shift frequently.
- Submit a new request with a reduced number of instances. For example, if you’re making a single request to launch 15 instances, try making 3 requests for 5 instances, or 15 requests for 1 instance instead.
- If you’re launching an instance, submit a new request without specifying an Availability Zone.
- If you’re launching an instance, submit a new request using a different instance type (which you can resize at a later stage). For more information, see Changing the instance type.
- If you are launching instances into a cluster placement group, you can get an insufficient capacity error. For more information, see Placement group rules and limitations.
- Try creating an On-Demand Capacity Reservation, which enables you to reserve Amazon EC2 capacity for any duration. For more information, see On-Demand Capacity Reservations.
- Try purchasing Reserved Instances, which are a long-term capacity reservation. For more information, see Amazon EC2 Reserved Instances.
Instance terminates immediately:
Your instance goes from the pending state to the terminated state immediately after restarting it. Following are a few reasons why an instance might immediately terminate, they are mostly related to EBS
- You’ve reached your EBS volume limit.
- An EBS snapshot is corrupt.
- The root EBS volume is encrypted and you do not have permissions to access the KMS key for decryption.
- The instance store-backed AMI that you used to launch the instance is missing a required part (an image.part.xx file).
Instance Types
General Purpose Instances: A1, M5, M5a,M6g ,T2, T3, T3a
A1 instances are for web severs and Container micro services
M5 and M5a instances are for Small and midsize databases, Data processing tasks that require additional memory, Caching fleets and Backend servers for SAP, Microsoft SharePoint, cluster computing, and other enterprise applications
M6g instances are for Application servers, Microservices, Gaming servers, Midsize data stores and Caching fleets
T2, T3, and T3a instances are for Websites and web applications, code repo, Dev & Test build environments and Microservices
These instances are well suited for the following:
Batch processing workloads, Media transcoding, High-performance web servers, High-performance computing (HPC), Scientific modeling, Dedicated gaming, servers and ad serving engines, Machine learning inference and other compute-intensive applications
Memory optimized instances: R5, R5a, ,R5n X1, X1e and Z1
R5, R5a, and R5n instances are for High-performance, relational (MySQL) and NoSQL (MongoDB, Cassandra) databases; Distributed web scale cache stores that provide in-memory caching of key-value type data (Memcached and Redis), In-memory databases like SANA, Applications performing real-time processing of big unstructured data (financial services, Hadoop/Spark clusters), High-performance computing (HPC) and Electronic Design Automation (EDA) applications.
X1 instances are for SAP HANA, Big-data processing engines such as Apache Spark or Presto, High-performance computing (HPC) applications.
X1e instances are for SAP HANA, High-performance databases and Memory-intensive enterprise applications.
z1d instances are for Electronic Design Automation (EDA) and Relational database workloads
Storage optimized instances: D2, H1, I3, I3en
D2 instances are for Massive parallel processing (MPP) data warehouse, MapReduce and Hadoop distributed computing and Log or data processing applications
H1 instances are for Data-intensive workloads such as MapReduce and distributed file systems, Applications requiring sequential access to large amounts of data on direct-attached instance storage and Applications that require high-throughput access to large quantities of data
I3 and I3en instances are for High frequency online transaction processing (OLTP) systems, Relational databases, NoSQL databases, Cache for in-memory databases (for example, Redis), Data warehousing applications and Distributed file systems
General purpose instances are for web applications, Compute instances are for computations work loads like Batch processing, Memory optimized instances are for Memory intensive high performance applications like RDBS, Cache stores and Storage optimized instances are for Big data processing applications
ASG Default Termination Policy
The default termination policy is designed to help ensure that your instances span Availability Zones evenly for high availability. The default policy is kept generic and flexible to cover a range of scenarios.
The default termination policy behavior is as follows:
- Determine which Availability Zones have the most instances, and at least one instance that is not protected from scale in.
- Determine which instances to terminate so as to align the remaining instances to the allocation strategy for the On-Demand or Spot Instance that is terminating. This only applies to an Auto Scaling group that specifies allocation strategies.For example, after your instances launch, you change the priority order of your preferred instance types. When a scale-in event occurs, Amazon EC2 Auto Scaling tries to gradually shift the On-Demand Instances away from instance types that are lower priority.
- Determine whether any of the instances use the oldest launch template or configuration:
- [For Auto Scaling groups that use a launch template]Determine whether any of the instances use the oldest launch template unless there are instances that use a launch configuration. Amazon EC2 Auto Scaling terminates instances that use a launch configuration before instances that use a launch template.
- [For Auto Scaling groups that use a launch configuration]Determine whether any of the instances use the oldest launch configuration.
- After applying all of the above criteria, if there are multiple unprotected instances to terminate, determine which instances are closest to the next billing hour. If there are multiple unprotected instances closest to the next billing hour, terminate one of these instances at random.Note that terminating the instance closest to the next billing hour helps you maximize the use of your instances that have an hourly charge. Alternatively, if your Auto Scaling group uses Amazon Linux or Ubuntu, your EC2 usage is billed in one-second increments. For more information, see Amazon EC2 Pricing.
Example
Consider an Auto Scaling group that uses a launch configuration. It has one instance type, two Availability Zones, a desired capacity of two instances, and scaling policies that increase and decrease the number of instances by one when certain thresholds are met. The two instances in this group are distributed as follows.

When the threshold for the scale-out policy is met, the policy takes effect and the Auto Scaling group launches a new instance. The Auto Scaling group now has three instances, distributed as follows.

When the threshold for the scale-in policy is met, the policy takes effect and the Auto Scaling group terminates one of the instances. If you did not assign a specific termination policy to the group, it uses the default termination policy. It selects the Availability Zone with two instances, and terminates the instance launched from the oldest launch configuration. If the instances were launched from the same launch configuration, the Auto Scaling group selects the instance that is closest to the next billing hour and terminates it.
ASG Customizing the Termination Policy
You have the option of replacing the default policy with a customized one to support common use cases like keeping instances that have the current version of your application.
When you customize the termination policy, if one Availability Zone has more instances than the other Availability Zones that are used by the group, your termination policy is applied to the instances from the imbalanced Availability Zone. If the Availability Zones used by the group are balanced, the termination policy is applied across all of the Availability Zones for the group.
Amazon EC2 Auto Scaling supports the following custom termination policies:
OldestInstance. Terminate the oldest instance in the group. This option is useful when you’re upgrading the instances in the Auto Scaling group to a new EC2 instance type. You can gradually replace instances of the old type with instances of the new type.NewestInstance. Terminate the newest instance in the group. This policy is useful when you’re testing a new launch configuration but don’t want to keep it in production.OldestLaunchConfiguration. Terminate instances that have the oldest launch configuration. This policy is useful when you’re updating a group and phasing out the instances from a previous configuration.ClosestToNextInstanceHour. Terminate instances that are closest to the next billing hour. This policy helps you maximize the use of your instances that have an hourly charge.Default. Terminate instances according to the default termination policy. This policy is useful when you have more than one scaling policy for the group.OldestLaunchTemplate. Terminate instances that have the oldest launch template. With this policy, instances that use the noncurrent launch template are terminated first, followed by instances that use the oldest version of the current launch template. This policy is useful when you’re updating a group and phasing out the instances from a previous configuration.AllocationStrategy. Terminate instances in the Auto Scaling group to align the remaining instances to the allocation strategy for the type of instance that is terminating (either a Spot Instance or an On-Demand Instance). This policy is useful when your preferred instance types have changed. If the Spot allocation strategy islowest-price, you can gradually rebalance the distribution of Spot Instances across your N lowest priced Spot pools. If the Spot allocation strategy iscapacity-optimized, you can gradually rebalance the distribution of Spot Instances across Spot pools where there is more available Spot capacity. You can also gradually replace On-Demand Instances of a lower priority type with On-Demand Instances of a higher priority type.